数据湖Iceberg-简介(1)
数据湖Iceberg-简介(1)
[toc]
数据湖Iceberg-简介(1) (opens new window) 数据湖Iceberg-存储结构(2) (opens new window) 数据湖Iceberg-Hive集成Iceberg(3) (opens new window) 数据湖Iceberg-SparkSQL集成(4) (opens new window) 数据湖Iceberg-FlinkSQL集成(5) (opens new window) 数据湖Iceberg-FlinkSQL-kafka类型表数据无法成功写入(6) (opens new window) 数据湖Iceberg-Flink DataFrame集成(7) (opens new window)
# Iceberg简介
# 概述
为了解决数据存储和计算引擎之间的适配的问题,Netflix开发了Iceberg,2018年11月16日进入Apache孵化器,2020 年5月19日从孵化器毕业,成为Apache的顶级项目。
Iceberg是一个面向海量数据分析场景的开放表格式(Table Format)。表格式(Table Format)可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark...)之下,数据文件之上。
# 特性
# 数据存储、计算引擎插件化
Iceberg提供一个开放通用的表格式(Table Format)实现方案,不和特定的数据存储、计算引擎绑定。目前大数据领域的常见数据存储(HDFS、S3...),计算引擎(Flink、Spark...)都可以接入Iceberg。
在生产环境中,可选择不同的组件搭使用。甚至可以不通过计算引擎,直接读取存在文件系统上的数据。
# 实时流批一体
Iceberg上游组件将数据写入完成后,下游组件及时可读,可查询。可以满足实时场景.并且Iceberg同时提供了流/批读接口、流/批写接口。可以在同一个流程里, 同时处理流数据和批数据,大大简化了ETL链路。
# 数据表演化(Table Evolution)
Iceberg可以通过SQL的方式进行表级别模式演进。进行这些操作的时候,代价极低。 不存在读出数据重新写入或者迁移数据这种费时费力的操作。
比如在常用的Hive中,如果我们需要把一个按天分区的表,改成按小时分区。此时,不能再原表之上直接修改,只能新建一个按小时分区的表,然后再把数据Insert到新的小时分区表。而且,即使我们通过Rename的命令把新表的名字改为原表,使用原表的上次层应用, 也可能由于分区字段修改,导致需要修改 SQL,这样花费的经历是非常繁琐的。
# 模式演化(Schema Evolution)
Iceberg支持下面几种模式演化:
- ADD:向表或者嵌套结构增加新列
- Drop:从表中或者嵌套结构中移除一列
- Rename:重命名表中或者嵌套结构中的一列
- Update:将复杂结构(struct, map<key, value>, list)中的基本类型扩展类型长度, 比如tinyint修改成int.
- Reorder:改变列或者嵌套结构中字段的排列顺序
Iceberg保证模式演化(Schema Evolution)是没有副作用的独立操作流程, 一个元数据操作, 不会涉及到重写数据文件的过程。具体的如下:
- 增加列时候,不会从另外一个列中读取已存在的的数据
- 删除列或者嵌套结构中字段的时候,不会改变任何其他列的值
- 更新列或者嵌套结构中字段的时候,不会改变任何其他列的值
- 改变列列或者嵌套结构中字段顺序的时候,不会改变相关联的值
在表中Iceberg 使用唯一ID来定位每一列的信息。新增一个列的时候,会新分配给它一个唯一ID, 并且绝对不会使用已经被使用的ID。
使用名称或者位置信息来定位列的, 都会存在一些问题, 比如使用名称的话,名称可能会重复, 使用位置的话, 不能修改顺序并且废弃的字段也不能删除。
# 分区演化(Partition Evolution)
Iceberg可以在一个已存在的表上直接修改,因为Iceberg的查询流程并不和分区信息直接关联。
当我们改变一个表的分区策略时,对应修改分区之前的数据不会改变, 依然会采用老的分区策略,新的数据会采用新的分区策略,也就是说同一个表会有两种分区策略,旧数据采用旧分区策略,新数据采用新新分区策略, 在元数据里两个分区策略相互独立,不重合。
在查询数据的时候,如果存在跨分区策略的情况,则会解析成两个不同执行计划,如Iceberg官网提供图所示:
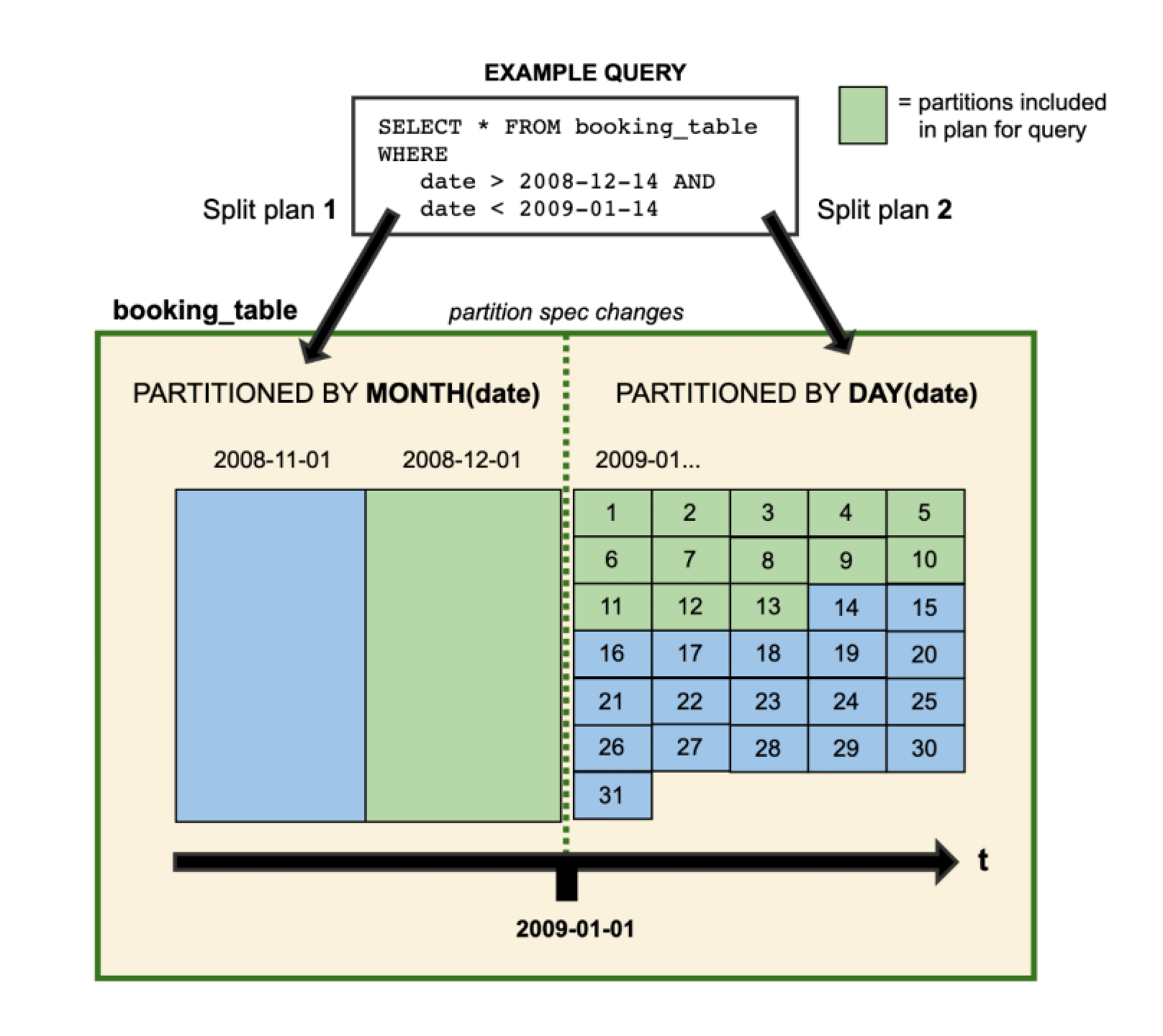
图中booking_table表2008年按月分区,进入2009年后改为按天分区,这两中分区策略共存于该表中。
借助Iceberg的隐藏分区(Hidden Partition),在写SQL 查询的时候,不需要在SQL中特别指定分区过滤条件,Iceberg会自动分区,过滤掉不需要的数据。
Iceberg分区演化操作同样是一个元数据操作, 不会重写数据文件。
# 列顺序演化(Sort Order Evolution)
Iceberg可以在一个已经存在的表上修改排序策略。修改了排序策略之后, 旧数据依旧采用老排序策略不变。往Iceberg里写数据的计算引擎总是会选择最新的排序策略, 但是当排序的代价极其高昂的时候, 就不进行排序了。
# 隐藏分区(Hidden Partition)
Iceberg的分区信息并不需要人工维护, 它可以被隐藏起来. 不同其他类似Hive 的分区策略, Iceberg的分区字段/策略(通过某一个字段计算出来),可以不是表的字段和表数据存储目录也没有关系。在建表或者修改分区策略之后,新的数据会自动计算所属于的分区。在查询的时候同样不用关系表的分区是什么字段/策略,只需要关注业务逻辑,Iceberg会自动过滤不需要的分区数据。
正是由于Iceberg的分区信息和表数据存储目录是独立的,使得Iceberg的表分区可以被修改,而且不和涉及到数据迁移。
# 镜像数据查询(Time Travel)
Iceberg提供了查询表历史某一时间点数据镜像(snapshot)的能力。通过该特性可以将最新的SQL逻辑,应用到历史数据上。
# 支持事务(ACID)
Iceberg通过提供事务(ACID)的机制,使其具备了upsert的能力并且使得边写边读成为可能,从而数据可以更快的被下游组件消费。通过事务保证了下游组件只能消费已commit的数据,而不会读到部分甚至未提交的数据。
# 基于乐观锁的并发支持
Iceberg基于乐观锁提供了多个程序并发写入的能力并且保证数据线性一致。
# 文件级数据剪裁
Iceberg的元数据里面提供了每个数据文件的一些统计信息,比如最大值,最小值,Count计数等等。因此,查询SQL的过滤条件除了常规的分区,列过滤,甚至可以下推到文件级别,大大加快了查询效率。
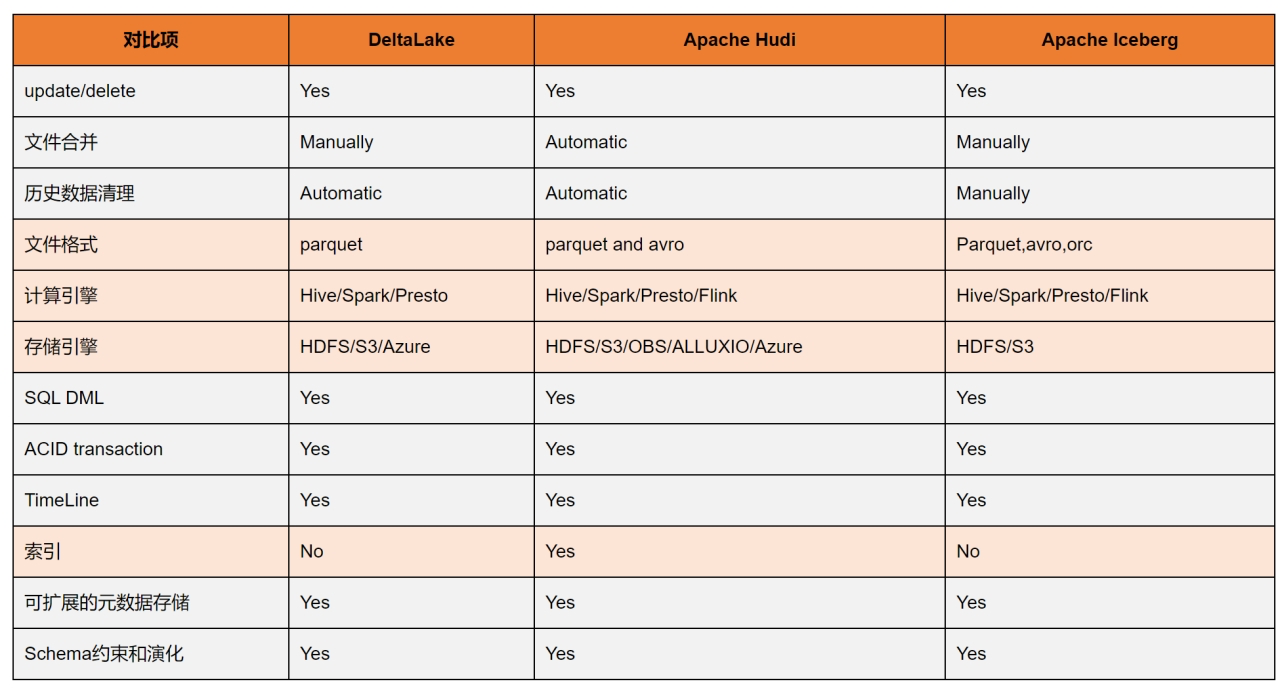
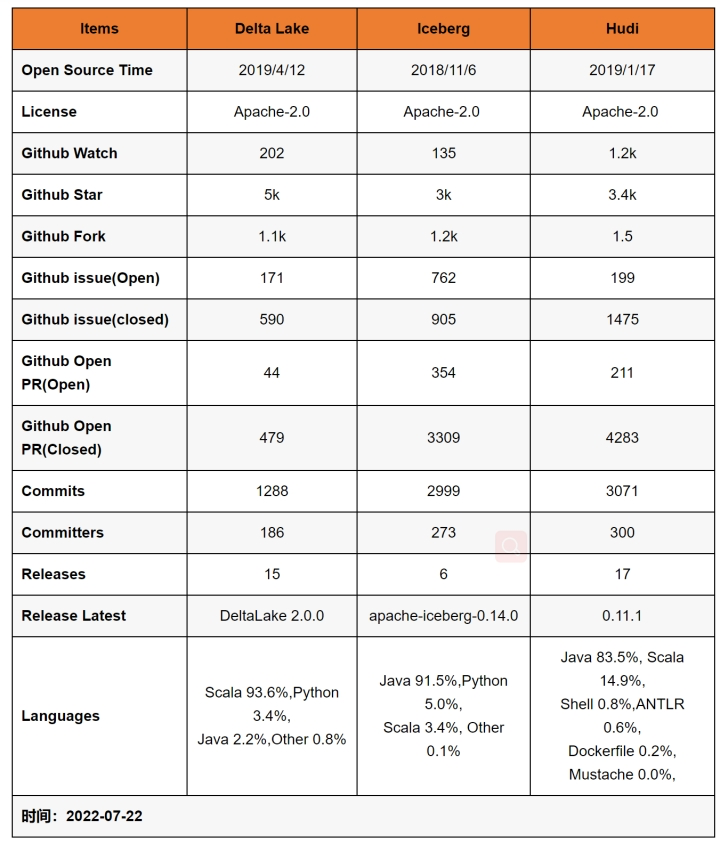
# 其他数据湖框架的对比